
The most important responsibility of the Wikimedia Foundation’s Technology department is to “keep the servers running”: to operate the computers that provide Wikipedia and other Wikimedia sites.
But running the servers is only a fraction of the work our eighty-person team does. The Technology department also provides a variety of other essential services and platforms to the rest of the Wikimedia Foundation and to the public. In this post, we’ll introduce you to all of the programs that make up the Technology department, and highlight some of our work from the past year.
The 18 members of the Technical Operations team maintain the servers and run the wikis. Over the last year, the team delivered an uptime of 99.97% (according to independent monitoring) across all wikis. The team also practiced switching the wikis back and forth between data centers, so that the sites are resilient in case of site failure. This year, they performed the second ever switchover from primary to secondary data center and back, and more than doubled the speed of the switchover (more information).
The ten-person Fundraising Technology team is responsible for the security, stability, and development of the Wikimedia Foundation’s online donation systems. Millions of relatively small donations (average of about $15 per transaction) make up the majority of the Wikimedia Foundation’s operating budget every year. The team maintains integration with 6 major payment processors, and several smaller ones, enabling online fundraising campaigns in approximately 30 countries each year. The team also maintains donor databases and other tools supporting fundraising.
You may have noticed that saving edits on Wikimedia got faster last year. For this, credit the Performance team. Last year, they tackled technical debt, and focused on the most central piece of our code’s infrastructure, MediaWiki Core, looking for the highest value improvements to make biggest performance impact.The four-person team was responsible for 27% of all contributions to MediaWiki Core last year (source). Their biggest success was reducing the time to save an edit by 15% for the median and by 25% for the 99th percentile (the 1% slowest edit saves). This is a performance improvement directly felt by all editors of our wikis.
The eight people on the Release Engineering team (RelEng) maintain the complicated clusters of code and servers needed to deploy new versions of Mediawiki and supporting services to the servers and to monitor the results. Last year they consolidated to a single deployment tool, which we expect to permanently reduce the cost of Wikimedia website maintenance. A creeping increase in maintenance costs is a major Achilles’ heel (“a weakness in spite of overall strength, which can lead to downfall”) of complex websites, so any improvement there is a major victory.
It’s hard to know if you are improving something if you can’t measure the improvement, and you can’t measure improvements to something you aren’t measuring in the first place. For example, the English Wikipedia community is experimenting with a different model for creating articles (ACTRIAL), and will need reliable data to know what the result of the experiment actually is. The seven-person Analytics Engineering team builds and supports measurement tools that support this and many other uses, while working within the Privacy Policy and the values of the movement that constrain what data can be collected. The team is working in new initiatives to process data real time that, for example, enable the fundraising team to get same-day turnaround on questions about fundraising effectiveness. One of the main projects this year is Wikistats 2. Wikistats has been the canonical source of statistics for the Wikimedia movement since its inception. Wikistats 2 has been redesigned for architectural simplicity, faster data processing, and a more dynamic and interactive user experience. The alpha for the UI and new APIs was launched in December 2017. Although the tool and APIs are geared to the community, anyone can use Wikistats UI and APIs to access information about Wikipedia.
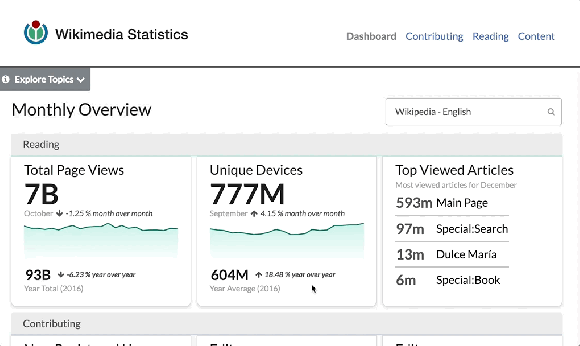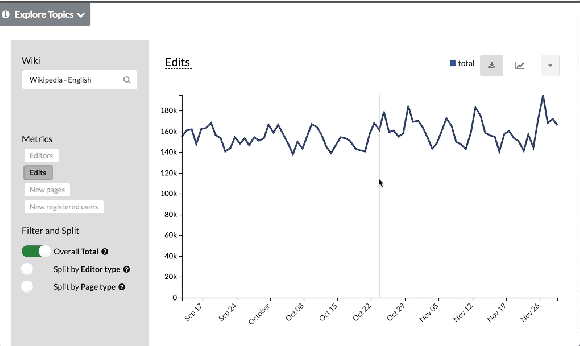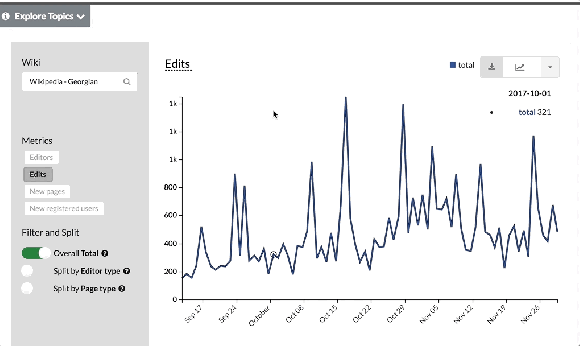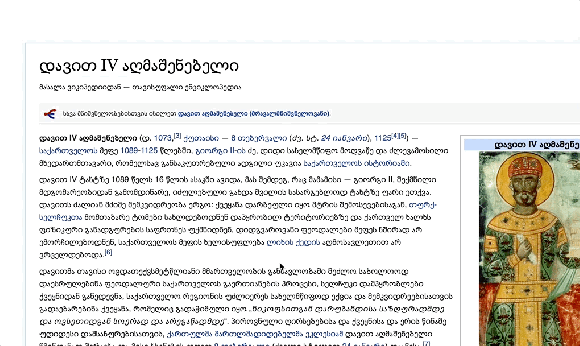
Picture of the Wikistats UI, accessible at http://stats.wikimedia.org/v2.
The Initiative for Open Citations, one of the projects led by the Research team, made citation data from 16 million papers freely available. Thanks to this grassroots initiative, availability of citation data went from 1% to over 45% of the scientific literature. We created a coalition of 60+ partner organizations, funders, publishers, tech platforms supporting the “unconstrained availability of scholarly citation data”. This data is actively being reused by volunteers in Wikidata. The Research team comprises six people, working on this among many other projects.

A list of organizations that support the Initiative for Open Citations. Logos drawn from the organizations identified, with most being non-free and/or trademarked.
The six people on the Search team work to make it easier to to find information on MediaWiki sites. Recently they have been focusing on integrating machine learning to drastically reduce the time needed to tune search results. The hypothesis is that it should go from taking 2 or 3 days of manually tweaking interdependent algorithms to taking an hour or two to set up new search ranking features in a given model. We are focusing on automating as much of this process as possible by the end of Q2. While we are too early in the deployment phase to enjoy a significant time reduction, we do know that machine learning is already showing a 5-6% improvement in search result clickthroughs, according to our initial tests on the English Wikipedia, using the same set of features we have been manually tuning up to this point (analysis). Ultimately, we will be able to deploy machine learning models on a per-wiki basis, whereas our manual approach is tuned against the English Wikipedia only and applied across the board based on that.
While traffic on Wikimedia sites are still served overwhelmingly as pages, we also serve high volumes of traffic via APIs. The Action API supports users such as bots, the mobile apps, and large content consumers like Google. The architecture of Mediawiki itself is also changing so that many “internal” human-facing features, such as VisualEditor and Page Previews, are also powered under the covers by the same API service; in this model, Wikimedia provides raw data and shifts the rendering burden to the client, i.e. VisualEditor or other in-browser tools, the mobile apps, or the third-party user. This infrastructure is the responsibility of the three people in the Services Platform team. This year they released version 1.0 of the REST API. This new API was engineered to support high-volume content and data access, as well as new use cases such as VisualEditor and section-level editing. It was growing rapidly even before version 1.0 (see chart). In the first 27 days of September 2017, it served 14.3 billion requests, compared to 14.9 billion for Action API. The release of version 1.0 signals commitment and maturity to the API user community commensurate with growth in traffic, and prepares WMF sites for high-volume API-driven experiences.
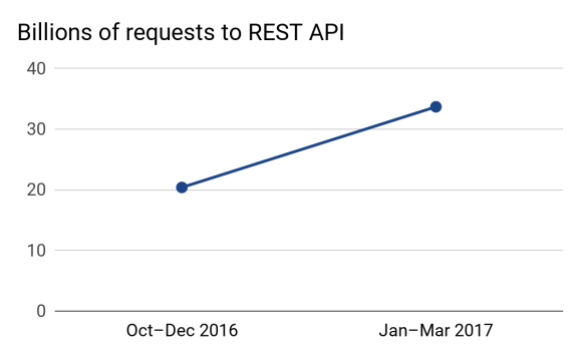
Graph, public domain.
This list of recent highlights captures only a fraction of the output of the Technology Department’s programs. In future blog posts, we’ll talk more about what the department is working on, what it’s planning to do, and how you can participate in the open-source production of Mediawiki software and the sustainment of the Wikipedia family of websites.
Victoria Coleman, Chief Technology Officer, Wikimedia Foundation, with assistance from many members of the Foundation’s Technology department.
This post has been updated to shorten the conclusion.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation