_-_Google_Art_Project.jpg){kind=link}
Don’t repeat yourself
The Android and iOS Wikipedia apps both offer similar polished native experiences to Wikipedians around the world. Usually, building an identical feature on different platform requires duplicating work effort with different source code written by different people and each with bugs unique to their implementations. This means that for each new feature, the expense to develop and maintain it must be paid not once but twice and a bug fixed on one doesn’t necessarily translate to the other.[1] Additionally, it is common that only a given platform’s developers are sufficiently proficient at programming for that target so multiple parties are often involved even for seemingly trivial changes.
This is where the Wikimedia page library comes in. The page library is a new project by the Wikimedia Readers department to share development and design resources between different software projects, starting with the Wikipedia native applications. The goals of the project are to:
- Share features and talent: New features are invested in once by a cross-team contributor pool that can focus on a single implementation providing a consistent and accurate experience across all platforms.
- Reduce bugs and maintenance: The consolidation of duplicate code has already greatly helped to eliminate flaws and each enhancement is propagated to all platforms.
- Improve stability: Testing page content (“anything in the browser”) for Android and iOS in a scalable way has historically been particularly challenging, flaky, and error prone. The page library has initially provided numerous DOM state unit tests for transforms as well as integration demos, and, in the long term, may also provide integration tests for transforms and visual regression integration tests at the component level.
- Make changes easier and safer: In general, changes to common code do not require expertise in Vagrant, Android, or iOS to make and separating platform concerns keep effects predictable and tests performant and sustainable. Additionally, we have started to consolidate the current cascade of style inheritances across multiple projects.
- Update page presentation with page content and independently of app updates: The library is versioned independently of the apps and may eventually be provided remotely so fixes and improvements could be published continuously on the fly.
Working together on a concerted effort maximizes the impact of each contributor and the quality of each product and it’s not without precedent either. After an initial investment to consolidate and clarify sources into the library, every consumer reaps the benefits. The page library is currently used in production for both the Android and iOS apps for theming content, enlarging images, and much more. It’s already planned to be used by the upcoming Page Content Service which is the future endpoint for Wikipedia clients including the Android, iOS, and even web apps.
The remainder of this article will discuss the development of a new page library feature, optimized image loading, also known as lazy loading.
What is lazy loading?

There are many different strategies that can be employed to improve image loading for webpages, a common performance bottleneck many websites must optimize for, especially for mobile users. One strategy that dramatically decreases the page load time and reduces the average number of bytes sent is called lazy loading. This technique involves initially replacing large images with placeholder content such as the grey boxes above. When a user first visits the web page, their browser only downloads the images within view. Offscreen images are then gradually loaded as the user scrolls further into the content (or never if they only view a portion of it). Lazily loading images on demand, as opposed to eagerly loading all of them, was shown to be enormously effective for Wikipedia users around the world, as well the efficiency of Wikipedia’s own data centers, when introduced on mobile web over a year ago.
Jon Robson covered the Readers’ Web team implementation of lazy loading images last year in a fantastic piece, “How Wikimedia helped mobile web readers save on data”. The native apps share many of the same concerns as mobile web so there was a strong desire for this functionality on both Android and iOS. The next sections will describe differences from the original web implementation.
What’s new in lazy loading?
When we first considered adding lazy loading to the native apps, we wanted to repeat the Web team’s success but, as a previous section mentioned, only write it once. Ideally, the page library would simply reuse the web’s implementation as is but unfortunately that was impractical. The web’s server implementation was written in PHP which isn’t supported by frontend clients (the native apps or browsers in general) and jQuery is a dependency of the web’s client implementation which the native apps otherwise do not need.
Since a rewrite was necessary, the choice of which language to use quickly came to the forefront. Although it was pragmatically the only option as a truly universal language for smartphone apps, desktop web browsers, server farm services, and beyond, JavaScript was a natural choice because it goes so well with webpage content, has a plethora of tools, an extraordinarily active community of developers, and a great quantity of code to be shared was already written in it. According to some, JavaScript is “the lingua franca of the web“[2] for both front and backend development. Initially, the page library is for frontend usage only by the native apps. However, writing in JavaScript means that it’s already slated to be supported on the backend and any future browser usage.
To understand the changes needed for the page library implementation, it’s helpful to first broadly revisit the current web implementation which is delineated by server-side and client-side portions:
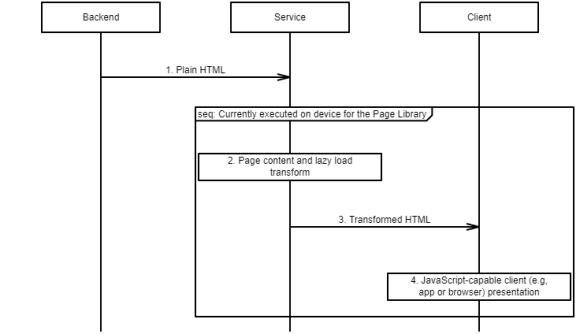
Plain HTML (1) is the input. The service (2) serves HTML as page content which includes transforming large images into economical grey placeholder boxes (3). The client (4) receives the content with the images already removed and may selectively re-add them by “undoing” the lazy load transform. At a high level, the page library works the same way except the service (2) is currently executed client-side too. In the future, the service (2) will move to the backend for improved performance but it will be identical code thanks to the ubiquitous quality of the page library’s JavaScript implementation.
Transform lifecycle: images to placeholders and back again
The service (2) replaces all images with spans and persists important attributes such as the image URL as data-* attributes which are application specific and untouched by clients. If the client displays this transformed HTML verbatim, all large images will be replaced with grey boxes. These are the spans. Pre-content presentation in this style is known as a skeleton screen and it looks kind of like a drawing of a newspaper in a comic style with lines and blocks instead of legible content:
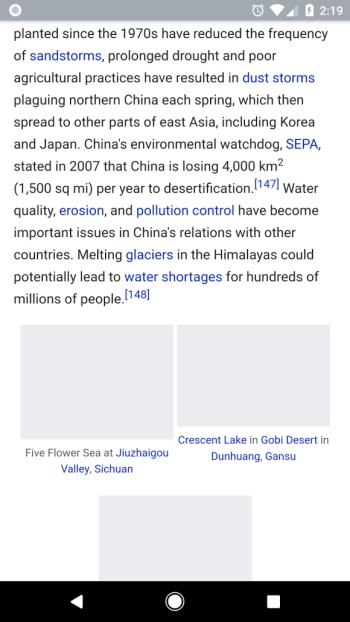
For a given image, the plain input HTML (1) may be:
<img width=100 height=200 src=picture.png>
And the transformed content HTML (3) would then be:
<span
class='pagelib_lazy_load_placeholder pagelib_lazy_load_placeholder_pending'
style='width: 100px'
data-width=100
data-height=200
data-src=picture.png>
<span style='padding-top: 200%'></span>
</span>
The anticipatory load distance is a couple screens on the Android client (4) so in reality the user will often never notice images that have yet be loaded. Placeholders are reevaluated for loading whenever the user scrolls. Loading simply means selectively undoing the transform applied by the service (2).

When an image is queued for downloading, the placeholder enters a loading state:
{kind=link}
{kind=link}
{kind=link}
<span
class='pagelib_lazy_load_placeholder pagelib_lazy_load_placeholder_loading'
style='width: 100px'
data-width=100
data-height=200
data-src=picture.png>
<span style='padding-top: 200%'></span>
</span>
This placeholder state is stylized as a pulsing grey box using performant CSS animations to cue a quick-scrolling user that the image is coming and will soon shimmer in. To actually start the download, an image element, just like prior to the transform, is also created at this time but is not attached to asynchronously load the picture behind the scenes:
<img class=pagelib_lazy_load_image_loading width=100 height=200 src=picture.png>
Finally, after a successful download the entire placeholder is replaced with the previously detached image:
<img class=pagelib_lazy_load_image_loaded width=100 height=200 src=picture.png>
Since a user’s connection may be poor, the page library also presents the error state distinctly. The placeholder enters an error state when loading fails:
<span
class='pagelib_lazy_load_placeholder pagelib_lazy_load_placeholder_error'
style='width: 100px'
data-width=100
data-height=200
data-src=picture.png>
</span>
And a click listener is provided for the user to retry the failed download when connectivity improves. This deviates from the web implementation.
Placeholder structure
There are many possible implementations for placeholders which are essentially rectangles:
- Replace the original image with a span and append a new downloaded image to the span.
This option has the best cross-fading and extensibility but makes duplicating all the CSS rules for the appended image impractical in the wild world of Wikipedia content possible.
- Replace the original image’s source with a transparent image and update the source from a new downloaded image.
This option has a good fade-in and minimal CSS concerns for the placeholder and image but causes significant reflows when used with image widening.
- Replace the original image with a span and replace the span with a new downloaded image.
This approach used by web has a good fade-in but has some CSS concerns for the placeholder, particularly max-width, and causes significant reflows when used with image widening.
- Replace the original image with a couple spans and replace the spans with a new downloaded image.
This is the current approach and about the same as the web but supports image widening without reflows.
Another implementation difference arose from performing what were server-side transforms on the client. Prior to displaying content, the native apps execute a variety of transforms to enhance the browsing experience. When lazy loading was considered, it was envisioned that this transform would be similar enough to the preexisting ones and maybe only the order would matter. However, one important difference emerged in that all the transforms require content HTML to be inflated into the DOM before they can execute. However, the nature of the lazy load transform is that it must strip all images prior to inflation to avoid eager downloads by the browser. The browser may download images at any time regardless of whether their elements are attached or a parentless tree. We solved this problem by performing the transform in a separate document entirely. This detail will vanish when the transforms are performed conventionally on in the context of a headless server like the web’s PHP implementation but it’s one of the few integration concerns not captured internally by the library for client-side transform usage.
Lastly, since the page library transforms are all written in JavaScript, a non-JavaScript client won’t execute them meaning that the web’s noscript fallbacks were unnecessary.
Outcome and the road ahead: the code so nice they wrote it once
On a fast connection, a user may never notice that images have been lazily loaded. On a slow connection, the user will hopefully only notice that the load time is nearly as good as on a fast connection with the anticipatory look ahead strategy balancing user experience against data savings. The end result is usually that the article contents are nearly unchanged but the data savings are excellent.
A surprise bonus effect of lazily loading images was seen on economy Android devices when viewing large articles with many images. Previously, these devices would stutter, become unresponsive, or even crash! With lazy loading, content loads promptly, on demand, and doesn’t exhaust memory.
Lazy loading is available today on the Wikipedia Android app and planned for the iOS app. The page library is already an integral part of both apps and in the future will also appear as a component of the Page Content Service. There are many transforms left to consolidate across platforms, new features to write, and bugs to fix. The page library makes it possible to ship high quality features across diverse platforms at a fraction of the cost. Don’t think twice, it’s al- … Actually, do think twice. Then code only once.
Stephen Niedzielski, Software Engineer
Wikimedia Foundation
Footnotes
- Note too that maintenance is equivalent to bringing a car into the mechanic’s for regular repair, sometimes commonplace and sometimes unexpected and expensive; software maintenance is a simple term for a recurring cost that comes with compound interest for the lifetime of a feature’s existence. It’s a big deal!
- A common language used to make communication possible between entities who do not share a native language.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation