
I first encountered the term “code health” in Max Kanat-Alexander’s post on the Google Testing Blog. It is simply defined as: “…how software was written that could influence the readability, maintainability, stability, or simplicity of code“.
The basic premise behind code health is that a developer’s quality of work, productivity, and overall happiness can be drastically improved if the code they work with is healthy.
That’s a pretty broad definition to say the least, but what’s equally important to the what code health is is the how it is then managed by a team. In Max’s post, he outlines how Google formed a small team called the Code Health Group. Each member of the team was expected to contribute an impactful percentage of their normal work efforts towards the Code Health Group’s priorities.
At the Wikimedia Foundation, we have formed a similar group. The Wikimedia Code Health Group (CHG) was launched in August 2017 with a vision of improving code health through deliberate action and support.
The CHG is made up of a steering committee, which plans to focus our improvement efforts towards common goals, and sub-project teams. The group will not only come up with prospective improvement initiatives, but be a conduit for others to propose improvements. The steering committee will then figure out staffing and needed resources, based on interest and availability of staff members.
In this post, I’ll talk a little bit about my definition of code health, and what we can do to manage it. Before that, however, I want to share why I became interested in working on this subject at the Foundation.
My deep dive into MediaWiki software
I’m a relatively new member of the Wikimedia Foundation—I joined the the Release Engineering team in January of 2017 with the goal of helping the Foundation and broader technical community improve its software development practices.
One of my first tasks was to understand our development practices and ecosystem, and I started by talking with developers who deeply understood MediaWiki — both in terms of what we did well and where there was room for improvement. My goal was to better understand the historical context for how MediaWiki was developed, and learn more about areas that we could improve. The result of these discussions are what I refer to as the “Quality Big Picture.” (I know, catchy name.)
What I learned during this discovery process was that there was room for improvement as well as a community of developers eager to improve the software.
Several weeks later, I had the opportunity to attend the Vienna Hackathon, where I hosted a session called “Building Better Software.” There, I shared what I had learned, and the room discussed areas of concern, including the quality of MediaWiki extensions and 3rd party deployments.
Other topics came up: I heard from long-time developers that some previous efforts to improve MediaWiki software lacked sustained support and guidance, and that efforts were ad-hoc and often completed by volunteers in their spare time.
The challenge was therefore two-fold: how to define and prioritize what to improve, and how to actually devote resources to make those improvements happen. It was these two questions that led me to Max’s blog post, and the subject of code health.
Let’s define “code health”
With some of the background laid out, I’d like to spend a little time digging into what “code health” means.
At a basic level, code health is about how easily software can be modified to correct faults, improve performance, or add new capabilities. This is broadly referred to as “maintainability”. What makes software maintainable? What are the attributes of maintainable software? This leads to another question: What enables developers to confidently and efficiently change code? Enabling developers after all, is what we are really targeting with code health.
Both a developer’s confidence and efficiency can vary depending on their experience with the codebase. But that also depends on the code health of the codebase. The lower the code’s health, then the more experience it takes for a developer to code with both confidence and efficiency. Trying to parse a codebase with low-code health is difficult enough for veteran developers, but it’s almost impossible for new/less experienced developers.
Interestingly, the more experienced a developer is with a code base, the more they want to see code health increase because code with lower health is more difficult and time-consuming to parse. In other words, high code health is good for both experienced and inexperienced developers alike.
Attributes
So what are the attributes of code health? For me, it boils down to four factors: simplicity, readability, testability, and buildability.
Simplicity
Let’s start with simplicity. Despite being subjective by nature, simplicity is the one attribute of code health that may be the most responsible for low code health. Fundamentally, simplicity is all about make code easier to understand. This goes against the common sentiment that because software is often written to solve complex problems, the code must be complex as well. However, that’s not always true: hard problems can be solved with code that’s easy to parse and understand.
Code Simplicity encompasses a number of factors. The size and signatures of functions, the use of certain constructs such as switch/case, and broader design patterns can all impact how easy a codebase is to understand and modify.
Despite its subjective nature, there are ways to measure code complexity such as the Cyclomatic and Halstead complexity measures. The former is already available against some of MediaWiki’s repos. But these tools come with a caveat because complexity measures can be misleading.
Readability
Another factor that affects code health is readability. Readability becomes more important as a development community grows in size. You can think of readability as the grammatical rules, sentence structures, and vocabulary that are present in any written human language.
Although a programming language’s syntax enforces a certain core set of rules, those rules are generally in place to provide a basic structure for a human to communicate with the computer, not another human. The paragraphs below are an example of how something can become significantly more complex without a common well understood set of rules. Given some time, you can still make sense of the paragraphs, but it is more difficult and error prone.
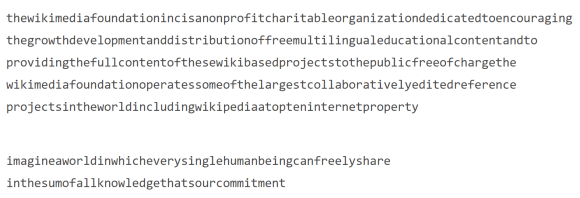
Much of what we see in-terms of poor readability is rooted in the not-so-distant history of programming. With limited computing resources such as processing, memory, and communication, programmers were encouraged to optimize code for the computer — not another human reader. But optimization is not nearly as important as it once was (There are always exceptions to that rule, however, so don’t set that in stone.). Today, developers can optimize their code to be human friendly with very little negative impact.
Examples of readability efforts include creating coding standards and writing descriptive function and variable names. It’s quite easy to get entangled in endless debate about the merit of one approach over another — for example, whether to use tabs or spaces. However, It’s more important to have a standard in place — whether it’s tabs or spaces — than to quibble about whether having a standard is useful. (It is.)
Although not all aspects of readability are easily measured, there is a fair amount of automated tooling that can assist in enforcing these standards. Where there are gaps, developers can encourage readability through regularly-scheduled code reviews.
Testability
Testability is often missing from many discussions regarding code health. I suspect that’s because the concept is often implied within other attributes. However, in my experience, if software is not developed with testability in mind, it generally results in software that is more difficult to test. This is not unlike other software attributes such as performance or scalability. Without some forethought, you’ll be rolling the dice in terms of your software’s testability.
I’ve found that it’s not uncommon for a developer to say that something is very difficult to test. Though this may sound like an excuse or laziness, it’s often pretty accurate. The question becomes: Could the software have been designed and/or developed differently to make it easier to test? Asking this question is the first step to make software testable.
Why should a developer change anything to make it easier to test? Remember the developer confidence I mentioned earlier? A big part of developer confidence when modifying code is based on whether or not they broke the product. Being able to easily test the code, preferably in an automated way, goes a long way to building confidence.
Buildability
The three attributes I’ve already mentioned are fairly well understood and are frequently mentioned when discussing healthy code. But there is a fourth attribute that I’d like to discuss. Code health is incomplete without including a discussion around Buildability, which I define as the infrastructure and ecosystem that the developer depends on to build and receive timely feedback on code changes they are submitting.
To be fair, you’d be hard pressed to find any material on code health that doesn’t mention continuous integration or delivery, but I think it’s important to elevate its importance in these discussions. After all, not being able to reliably build something and receive timely feedback hampers developer productivity, code quality, and overall community happiness.
The How
Now that we’ve talked about what code health is, we can discuss our next question: How do we address it? This is where we transition from talking about code to talking about people.
MediaWiki, like many successful software products/services, started with humble beginnings. Both its code base and developer base have grown as the Wikimedia projects have matured, and the personality of the code has evolved and changed as the code base expanded. All too often, however, this code is not refactored and “cruft”—or unwanted code—develops.
None of this of course is news to those of us at the Foundation and in the volunteer developer community that work on MediaWiki. There are many stories of individual or groups of developers going above and beyond to fix things and improve code health. However, these heroics are both difficult to sustain without formal support and resources, and often are limited in scope.
While speaking to developers during my first few months at the Foundation, I was inspired by what I heard, and I want to ensure that we’re working towards making these kinds of efforts to make our codebase more sustainable and even more impactful. Luckily, enabling developers is core to the mission of the Release Engineering team.
Simply forming the CHG isn’t sufficient. We also need to build momentum through ongoing action and feedback loops that ensure that we’re successful over the long-term. As a result, we’ve decided to take on the following engagement approach:
- The Code Health Group is now meeting on a regular cadence.
The goal of these monthly meetings is to discuss ongoing code health challenges, prioritize them, and spin up sub-project teams to work towards addressing them.
Agenda and notes from those meetings will be made available through the Code Health Group MediaWiki page.
Although the CHG has been formed and is meeting regularly, it’s far from complete. There will be plenty of opportunities for you to get involved over the coming months.
- We’ll share what we learn.
The CHG will look to provide regular knowledge sharing through a series of upcoming blog posts, tech talks, and conferences.
We anticipate that the knowledge shared will come from many different source both from within the MediaWiki community as well as the broader industry. If you have a code health topic that you’d like to share, please let us know.
- We plan to hold office hours.
For code health to really improve, we need to engage as a community, like we do for so many other things, and that involves regular communication.
Although we will fully expect and support ad hoc discussions to happen, we thought it might enable those discussions if we had some “office hours” where folks can gather on a regular basis to ask questions, share experiences, and just chat about code health.
These office hours will be held in IRC as well as a Google Hangout. Choose your preferred tech and swing on by. Check out the CHG Wiki page for more info.
What’s next?
Though the CHG is in a nascent stage, we’re happy with the progress we’ve made. We’re also excited about where we plan to go next.
One of the first areas we plan to focus on is identifying technical debt. Technical debt—which I’ll discuss in an upcoming series of posts—is closely aligned with code health. The newly launched Technical Debt Program will live within the Code Health Group umbrella. We believe that a significant portion of Technical Debt on MediaWiki is due to code health challenges. The technical debt reduction activities will help build sound code health practices that we will then be able to use to avoid incurring additional technical debt, and reducing what currently exists.
Over the coming weeks, we will be releasing a series of blog post on Technical Debt. This will be followed by a broader series of blog posts related to code health. As the code health hub, we’ll also share what we learn from the broader world. In the meantime, please don’t hesitate to reach out to us.
Jean-Rene Branaa, Senior QA Analyst, Release Engineering
Wikimedia Foundation
Thank you to Melody Kramer, Communications, for editing this post.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation