
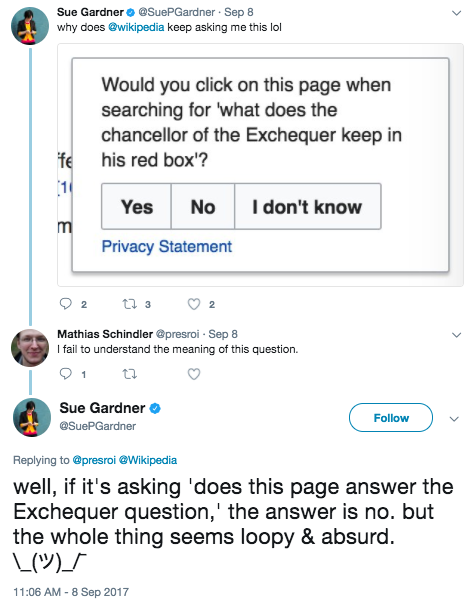
The Friday before last, Sue Gardner—the former head of this organization, of all people—discovered a survey-based experiment we were running on Wikipedia. She took a screenshot and shared it on Twitter, where she wrote that “the whole thing seems loopy [and] absurd.” The survey asked if the Wikipedia article she was reading, Despatch box, would be relevant “when searching for ‘what does the chancellor of the Exchequer keep in his red box’?”
While admittedly loopy, the question is not entirely absurd.
The Wikimedia Foundation’s Search Platform team hopes this survey question and others like it will allow us to gather useful data on the relevance of search results, which in turn will help improve the quality of search on Wikipedia—and importantly, not just on English Wikipedia.
The particular question Sue tweeted about features one of my favorite queries from the survey, because I didn’t know anything about the subject of despatch boxes before reading the query. There are probably only a couple of pages on English Wikipedia that are really relevant to the query, but we’re asking variations of this question about the Chancellor of the Exchequer on a few dozen pages.
Why? Machine learning!
Search, in two not-so-easy steps
While it’s oversimplifying a bit, you can think of searching for articles as having two major steps—first, find articles that contain words from the query, and second, rank those articles, ideally so that the most relevant result is listed at the top. The first step has some subtlety to it, but it is comparatively straightforward.
The second step is more complex because there is not a clear recipe to follow, but rather a lot of little pieces of evidence to consider. Some bits of evidence include:
- How common each individual word is overall. (As the most common word in the English language, the is probably less important to a query than somewhat rarer friggatriskaidekaphobia.)
- How frequently each word appears in a given article. (Five matches is probably better than four matches, right?)
- Whether there are any matching words in the title or a redirect. (Well, if you search for just the, an article on English’s definite article does look pretty good.)
- How close the words are to each other in the article or title. (Why is there a band called “The The”?)
- Whether words match exactly or as related forms. (The query term resume also matches both resuming and résumé.)
- How many words are in the query.
- How many words are in the article. (Okay, maybe five matches in a twenty thousand word article might be worse than four matches in a five hundred word article.)
- How often an article gets read. (Popular articles are probably better.)
- How many other articles link to an article. (Did I mention that popular articles are probably better?)
…and lots more!
Not only do you have to figure out how to weight these different pieces of evidence, you also have to figure out how best to measure them. Should popularity be measured over the last hour, week, or decade? A word that appears in three articles is rarer than a word that appears in thirty articles, but is a word that appears in 5,178,346 articles really that much rarer than a word that appears in 5,405,616 articles? (That would be the numbers for “of” and “the” on English Wikipedia at the time of this writing, but the numbers will likely go up before you get to the end of this sentence. Wikipedians are very industrious!)
At some point, manually tweaking the scoring formulas becomes too complex to be effective, and it becomes a never-ending game of whack-a-mole, with a fix over here causing a problem over there. There’s also the problem of applying any scoring formula to different projects or to projects in different languages, where the built-in estimates of the relative importance of any of the features in the scoring formula may not quite hold.
Machine learning to the rescue!
The solution—in just one oversimplified step—is to automate the process of determining the scoring function. That is, to use machine learning. Erik Bernhardson—a senior software engineer at the Foundation and technical lead for the search back-end team—got good results from his initial experiments and he, along with our colleague David Causse, and others outside the Foundation have been busy building a machine learning pipeline for search.
The problem is that machine learning needs data, lots of data—preferably all the data you can get your hands on, and then a bunch more data. And maybe a little extra data on top. Seriously though, more data gives the machine learning training process the evidence it needs to build a more nuanced, and thus more accurate model.
Importantly, a machine learning model needs to be trained and evaluated on both good examples and bad examples, otherwise it can learn some screwy things. Without bad examples, the machine learning process can’t know that tweaking something over here to get 5 more right answers also makes 942 wrong answers pop up over there. It needs to be able to see all the metaphorical rodents—uh, I mean, talpids—at once to figure out the best way to whack as many as possible.
Let’s make some noise data!
We tried generating human-curated training data using a cool tool called the Discernatron, built by Erik and subsequently prettified for use by humans by Jan Drewniak. The problem is that looking at other people’s queries is both very hard and very boring.
The hardest part is trying to figure out what people intended when they searched. A query like naval flags is so broad that it is hard to say what the most relevant article is.[1] A query like when was it found just doesn’t seem to refer to anything in particular—though it might be the name of a book or a play or an episode of an obscure TV show or a song by a band you never heard of (yeah, we’re search hipsters). Another favorite, tayps of wlding difats, is too hard to decipher for many people, but might be possible for a phonetic search to find—it seems to be a phonetic rendering of “types of welding defects”. But even if you do understand a given query, you may not know enough about the subject matter to judge the relevance of any articles.
There’s also the problem of noise in the Discernatron data. Even assuming good faith, you would expect people to disagree about what is relevant and what is not. Some queries are harder to decipher than others, and some people are also better at doing the deciphering. Unfortunately, that means that progress with the Discernatron was even slower than we’d hoped because we needed to get multiple reviews of the same data and come up with a way to determine whether different reviewers were in close enough agreement that their collective ratings constitute a consensus. We never got enough data for training, though we did build a nice data set for validating other approaches against.
Erik, never one to be deterred, started looking for ways to automate the data collection, too. Dynamic Bayesian networks (DBN)—in addition to being in the running for having the article with one of the w-i-d-e-s-t illustrations on the English Wikipedia—are the foundation for an approach that aggregates click-through data from similar searches to infer users’ collective relative preferences among search results. A good example is the TV series The Night Manager. Because the book that the series is based on is an exact title match when querying the night manager, it gets ranked above the TV show. But the DBN model made it abundantly clear that recently, at least, people were much more interested in the TV show.
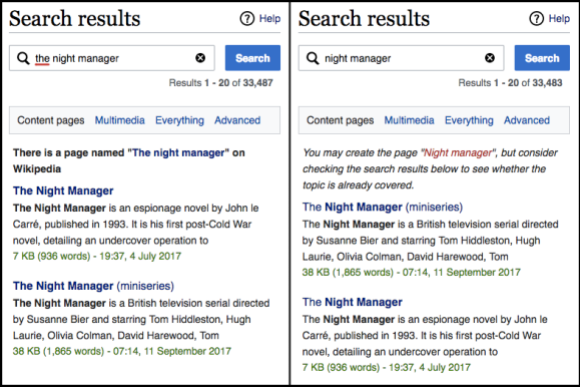
Dropping the from the query, the night manager, eliminates the exact title match and changes the rankings just a bit. Screenshots from the English Wikipedia, CC BY-SA 3.0 and/or GNU Free Documentation License.
However, there’s still a problem with the DBN method. It relies on multiple users looking for more or less the same thing to draw its inferences. Not only do we want to know what the most relevant result is for a given query, but also the relative relevance for as many of the other results as possible. For the night manager, the results were overwhelming—everyone wanted the TV series and nothing else—but the ranking of most results is more nuanced: there may be a clear favorite, but also relevant second and third place results, and maybe even relevant fourth and fifth place results. You can’t really get that info from a single user.
Another issue is a concern that maybe there’s a result down in twenty-seventh place that may not be the best of the best, but it’s still what some people are looking for. No one looks at the twenty-seventh result, except those of you who are going to read that and then go look at some random twenty-seventh result just to be contrarian. (Welcome; you are my people.)
Improve the best, but don’t forget the rest
So, we’re never going to get enough clicks to create DBN-based training data covering the long tail of less common queries, and we’re never going to get any clicks to help us find good results that are hiding too far down in the results list.
Nonetheless, the DBN-based models did as well as our current result-ranking scoring methods in recent tests: you can check out the report by data analyst Mikhail Popov. Searchers clicked more overall and clicked more on the first result, so we’re doing something right!
The machine learning models also offer more room for improvement. Future improvements will come from a feedback loop as the machine learning models bring some results up from lower down the list (based at first on the features they exhibit, not the clicks they received), and from new features we add to help identify and/or distinguish more promising results.
Still, we worry about the long tail. If ten thousand people don’t get any good results for one particular query, we’ll hear about it—or one of them will write a new article or create a redirect and solve the problem that way. (Industrious!) But if ten thousand people each fail to get any good results for ten thousand separate queries, we would likely never know, at least not about all of them.
Maybe it’ll turn out that queries and results in the long tail are just like the more common queries we see in the DBN-based training data, merely less popular. In that case, the generalizations the machine learning model makes based on the DBN-based data—exact title matches are always good; it’s okay for most of the query words to be “common” when the query is over 37 words long, but not when it is less than 4 words long; more inexact matches in the title plus lots of exact matches in the first paragraph are better than fewer exact matches in the title and no matches in the first paragraph; “Omphalos hypothesis” should always be the seventh result for every query on Thursdays[2]—will also apply to the long tail. But maybe the long tail is qualitatively different, too.
How the sausage is made
Erik, who is always full of good ideas, decided we could solve our lack of long-tail data by turning the Discernatron inside out. Instead of taking a query and asking users to review a bunch of articles that might be relevant, what if we take an article and ask a user to review a query that might be relevant? Hence the survey seen by Sue!
The survey has been simplified from the Discernatron in many ways. The only rating options are “relevant”, “not relevant”, and “get me out of here”. All of the instructions have been boiled down to the one question (though we are also running A/B/C/D/E/F/G/H/I/J/K/etc. sub-tests to find the best wording for the question). And we hope that by asking someone about an article they’ve been reading for a little while, some of the “real world knowledge” problems will be mitigated.
We’ve already completed a very limited round of surveys to see if people agreed with me (personally!) on the relevance of a few articles for a few queries that I made up—just to make sure the survey-based crowd-sourcing approach works. Mikhail’s analysis shows that (a) a small group of random strangers on the internet were able to roughly infer the intent of my queries and the relevance of possible results, and (b) they like to tell you that you are wrong more than they like to tell you that you are right—irrelevant articles get more engagement than relevant articles. (Though maybe people are being careful; sometimes it is easier to see that things are wildly wrong than possibly right.)
The current round of surveys is testing much more broadly, using the not-quite-so-small corpus of queries and consensus-ranked articles we have from the Discernatron data. Re-using the Discernatron data—much of which is long-tail queries—lets us validate our crowd-sourced survey-based approach by comparing the survey relevance rankings against the Discernatron relevance rankings.
End game
If the survey data and the Discernatron data look similar enough, we can confidently expand the survey to new queries and new articles. Ideally, we can generate enough long-tail data this way to fold it into the DBN-based data used for training new machine learning models, probably with some weighting tricks since it will never match the scope of the DBN-based click-through data. But even if we can’t, we can still use the survey-based data to validate the performance of the DBN-based models on long-tail data.
Once we’re reasonably confident that our survey method works for English, it will much easier to expand to other languages and other projects. While it will take some careful work to translate the survey question(s) and even more to vet potential queries (they have to be carefully screened by multiple people to make sure no personal information is inadvertently revealed), it’s much less work than has been put into building the Discernatron corpus in English, and for much more reward.
And, of course, our survey needs to include both good examples and bad examples—even the ones that seem more than a little loopy—in part because we need both loopy and non-loopy data for training and validation, and in part because if we could tell loopy and non-loopy apart, we wouldn’t need help from the Wikipedia community to find out what the Chancellor of the Exchequer has in his red box!
Parting thoughts
- In the spirit of Wikipedia and Wiktionary (my favorite!): Be bold! Try new ideas, new approaches, new features—test them!—and don’t fret if they don’t all work out on the first go, because…
- Machine learning generally and feature engineering specifically is a black art—and doubly so for search because there is no one right answer to work towards. Whatever was mentioned in that cool paper you read or came as the default settings in the open-source software you downloaded is not likely to be exactly what’s best for you and the data you love. Optimize, optimize, hyperoptimize!
- Whether you are using manual tuning or machine learning to improve search, good intuition and specific examples are very useful, but proper testing—and data that reflects what your users want[3] and need—is vital. Otherwise you are playing whack-a-mole in the dark.
- Communication is hard. The Discernatron offers two pages of documentation, but —like all documentation—nobody actually reads it. Our new survey has at most a couple dozen words in which to ask a question and motivate the reader to participate. Getting your point across without being boring or coming off as absurd is a difficult balance.
On Phabricator you can follow the not entirely absurd progress of the machine learning pipeline in general (see task T161632), and the search relevance surveys in particular (see task T171740). You can join in the discussion with questions and suggestions, too!
Trey Jones, Senior Software Engineer, Search Platform
Wikimedia Foundation
Footnotes
- More than one person has wisely suggested that the maritime flag article is the obvious answer here. Statistically, though, this was one of the Discernatron queries that reviewers disagreed on most.
- These are all made up and nothing as specific as a rule about a particular article is going to be learned by a machine learning model. We also don’t include the day of the week as a feature in the model—though given the differences in user behavior on weekdays and weekends, maybe one day we will (last Thursday, I predict)!
- Because—to paraphrase J. B. S. Haldane—what people search for is not only stranger than we imagine, it is stranger than we can imagine.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation