_pilot_with_Griffin_Aerospace,_tracks_a_RPVT_through_a_set_of_binoculars_during_a_live-fire_exercise_at_Onslow_Beach,_Camp_Lejeune,_N.C.,_March_19,_2014_140319-M-QZ288-185.jpg)
I spend a lot of time trying to figure out how search queries on different Wikipedias and other wiki projects can go wrong.
For examples: people look for non-encyclopedic information in an encyclopedia (like perfectly reasonable but non-encyclopedic information such as What makes a romantic date? or best sofa under $200), they accidentally cut-and-paste the wrong thing into the wrong box in the wrong tab of their browser (like, two-thirds of an essay on “Why School Spirit Is Important to Me”), or the software they are using has a bug somewhere (like the enigmatic quot Rasmus Rask quot or the abstractly useful {searchTerms}).[1]
Sometimes, though, people are searching for things that really look like gibberish. It’s hard to see how a query like hjkhjkhjkhjkhjkhjkhjkhjkhjk is supposed to lead to any kind of useful result. Similarly for %%%%%%%-.-**&@@ or mmmmmmmmmmmmmmmmmmnnm. Did the searcher fall asleep while typing or set a coffee mug down wrong? Should we blame the cat? It’s hard to say, although blaming the cat is generally a good fallback strategy.
On the other hand, there are also queries like fhbcnjntkm and ‘qatktdf ,fiyz and zgjybz. These are all real queries that I encountered, all from Russian Wikipedia, and at first glance they certainly look like gibberish. However, they are actually hiding their secrets from you, me, and Wikipedia’s search engine.
{kind=link}
Of keyboards and alphabets
There are lots of people in the world who speak more than one language. For those of us who haven’t ventured very far outside our native alphabet, it’s probably easier to keep “typing” and “using a language” as mostly unentangled skill sets. If I’m typing in French, I’m not going to switch to a French keyboard. I tried it once, and it did not go well—Where is the a? Why is the q there, and who would do such a thing? Do I use z or w for “undo”? Aaaa!

 United States QWERTY and French AZERTY keyboards by Denelson83 (US) and Yitscar, Michka B, and David96 (French), both CC BY-SA 3.0.
United States QWERTY and French AZERTY keyboards by Denelson83 (US) and Yitscar, Michka B, and David96 (French), both CC BY-SA 3.0.
On the other hand, if you are switching between languages that use different writing systems—Latin, Cyrillic, Arabic, Devanagari, Greek, Hangul, Hebrew, Kana, and many others—you have to do something. A nifty option is a phonetic keyboard, which maps the letters of one alphabet onto the keys of another based on sound similarity; these seem to be especially common for Russian, which is great for, say, English speakers learning Russian, or Russian speakers who mostly type on a non-Russian keyboard.
 Phonetic Russian keyboard layout by PavelSF, CC BY-SA 3.0.
Phonetic Russian keyboard layout by PavelSF, CC BY-SA 3.0.
Because consonants generally map to consonants and vowels generally map to vowels, using the wrong phonetic keyboard gives something that still looks like language and not gibberish. For example, if you type Русский while your keyboard is set to use Latin characters, you might get Russkij. If you type Wrong Keyboard while your keyboard is set to use Cyrillic characters, you might get Вронг Кеыбоард. In both cases the errors at least look more or less like words.
There are plenty of people, though, who type on standard keyboards in more than one language. They might, for example, use a typical American keyboard for English and a typical Russian keyboard for Russian. (Fortunately, for this and other combinations there are keyboards with both character sets displayed on the keys.) In such a case, the mapping between the character sets is more or less an arbitrary historical accident. Vowels and consonants across languages share no relationship, some letters are mapped to punctuation, and punctuation is all over the place. The space bar is probably in the same spot, thankfully.
Below is a one such possible mapping.
{kind=link}
 Side quest: Before you continue reading, try to decipher the apparently nonsense word in Cyrillic in the title of this post. If that’s too easy, figure out the three “gibberish” query examples above. Bonus points if you don’t speak Russian, and double bonus points if you use a wiki to help you figure it out.
Side quest: Before you continue reading, try to decipher the apparently nonsense word in Cyrillic in the title of this post. If that’s too easy, figure out the three “gibberish” query examples above. Bonus points if you don’t speak Russian, and double bonus points if you use a wiki to help you figure it out.
This is neat, but what can we do about it?
Repurposing language identification
Another way that searching can go wrong is when you search in a language that’s different from the language of the wiki you are on. Sometimes it works fine, especially with names of famous places (Москва) or well-known institutions (Académie française). On some Wikipedias, we have software in place to try to detect the language of a poorly performing query, search the appropriate Wikipedia, and return results from there. For example, on English Wikipedia, if you search for Spanish historiografía griega, you get one English result, plus a bunch of results from Spanish Wikipedia. (You can read more about this feature on this very blog, in a post titled “Wikipedia seeks to speak your language”.)
The models we use to do language identification can be readily adapted to detecting languages being typed on the wrong keyboard. In fact, using the mapping above, I was able to create a “Cyrillic English” model and a “Latin Russian” model. The distinctive patterns of each language are the same, just recast into another character set.
In the case of the three examples above—fhbcnjntkm and ‘qatktdf ,fiyz and zgjybz—they map respectively to аристотель, эйфелева башня, and япония. If you don’t speak Russian, you can use English Wiktionary to discover that they are Russian for “Aristotle”, “Eiffel Tower”, and “Japan”. The title of this post includes Цкщтп, which maps from Cyrillic to Latin Wrong, which Russian Wiktionary will tell you means “неправильный”. (Award yourself side quest bonus points as needed.)
A deeper dive and future plans
I first looked into this problem during the summer of 2016, originally focusing only on Russian and English as the situation was brought to my attention by a Russian-typing colleague. (More technical details are available in my write up on MediaWiki.) To validate the approach, I ran some tests on big samples of English and Russian Wikipedia queries, and added a number of filters to the process to improve accuracy: ignoring the more ambiguous results, ignoring very short results, and ignoring results that didn’t completely map from Cyrillic to Latin or vice versa.
“Cyrillic English”—that is, English words mistyped on a Russian/Cyrillic keyboard—was very rare in my sample of English Wikipedia queries (0.012%, with no false positives), but much more common among Russian Wikipedia queries (0.229%, but with a false positive rate of about 25%).
“Latin Russian”—Russian words mistyped on a English/Latin keyboard—was a big miss for English Wikipedia queries, with few examples and less than 5% accuracy, but it was a really big hit with Russian Wikipedia queries, with about 1.4% of all queries being typed on the “wrong” keyboard, and about 95% accuracy in identifying them! (Now for the “however”…)
However, we already have a number of so-called “second-try” searches for queries that seem to have gone wrong.
- Spelling correction / suggestions (a.k.a., “Did you mean”)—searching for albet on English Wikipedia gives some results, but also asks, “Did you mean: albert”
- Cross-wiki searching with language identification—as noted above, searching for historiografía griega on English Wikipedia gives results from Spanish Wikipedia, too.
- Sister project search—on many Wikipedias, the top results from other projects in the same language are shown in a sidebar. The example above, albet, gives results from Wiktionary, Wikiquote, and Wikisource.
All these suggestions and options are great, but the page starts to get a little crowded when there are too many of them at once. A somewhat artificial example on English Wikipedia maximizes the clutter: max planck wissenschaftliche sich night. It includes a “Did you mean” spelling suggestion, an offer to create an article with that name, one result from English Wikipedia, a sister project result from Wikiquote, and a bunch of results from German Wikipedia. A more natural example, with just one word—Puppenspielerin—has almost the same level clutter, except there’s no spelling correction. (Follow the link to see why sister project search in general, and Wiktionary in particular, are so wonderful!)
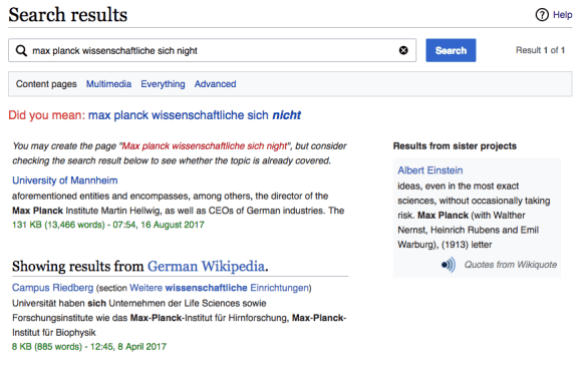 An example query on English Wikipedia that generates all of the current second-try search options. Wikimedia screenshot, CC BY-SA 3.0.
An example query on English Wikipedia that generates all of the current second-try search options. Wikimedia screenshot, CC BY-SA 3.0.
Before we can add more ways to help with searches gone wrong, we need to build out our second-try search infrastructure to support prioritizing the available methods and dealing with potential interactions between them. We have to consider user interface and display issues, computational costs, and user-perceived latency.
You can follow the progress of Russian/English wrong keyboard detection—and join the conversation!—on Phabricator ticket T138958. It’s also been suggested that Hebrew and English could benefit from a similar treatment (see Phab ticket T155104).
Please suggest other language/keyboard pairs with the potential for this problem—Ukrainian, Greek, Arabic, Armenian?—and not only ones paired with English, of course. The discussion of second-try searches in general is happening on Phab ticket T156019, which includes links to a wiki page with more details.
Happy searching!
Trey Jones, Senior Software Engineer, Search Platform
Wikimedia Foundation
Footnotes
- For those who are wondering, quot likely comes from someone searching using quotes—e.g., “Rasmus Rask”—then some software that’s too smart for its own good converted the quotes to character entities—i.e.,
"—and then “sanitized” those by stripping the ampersand and semicolon, et voila! OpenSearch and similar templated schemes use placeholders like {searchTerms} to indicate where the search terms should be put into an API call or URL. It looks like someone forgot to replace the placeholder.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation