
The Wikimedia REST API (try it on the English Wikipedia) offers access to Wikimedia’s content and metadata in machine-readable formats. Focused on high-volume use cases, it tightly integrates with Wikimedia’s globally distributed caching infrastructure. As a result, API users benefit from reduced latencies and support for high request volumes. For readers, this means that content in apps and on the web loads more quickly. Editors have a more fluid and intuitive VisualEditor experience. Researchers and bot authors can work with Wikimedia content at volume, using formats that are widely supported.
The release of version 1 officially sees the REST API ready for stable production use. After two years of beta production, serving approximately 15 billion requests per month, we are now publicly committing to the stability guarantees set out in our versioning policy. Each entry point has a stability level ranging from experimental to stable. Experimental end points are subject to change without notice, while changes to unstable end points will be announced well in advance. Stable entry points are guaranteed to keep working for the lifetime of the v1 API as a whole. To allow for minor changes in the returned content formats without breaking clients, content types are versioned, and content negotiation using the HTTP Accept header is supported.
———
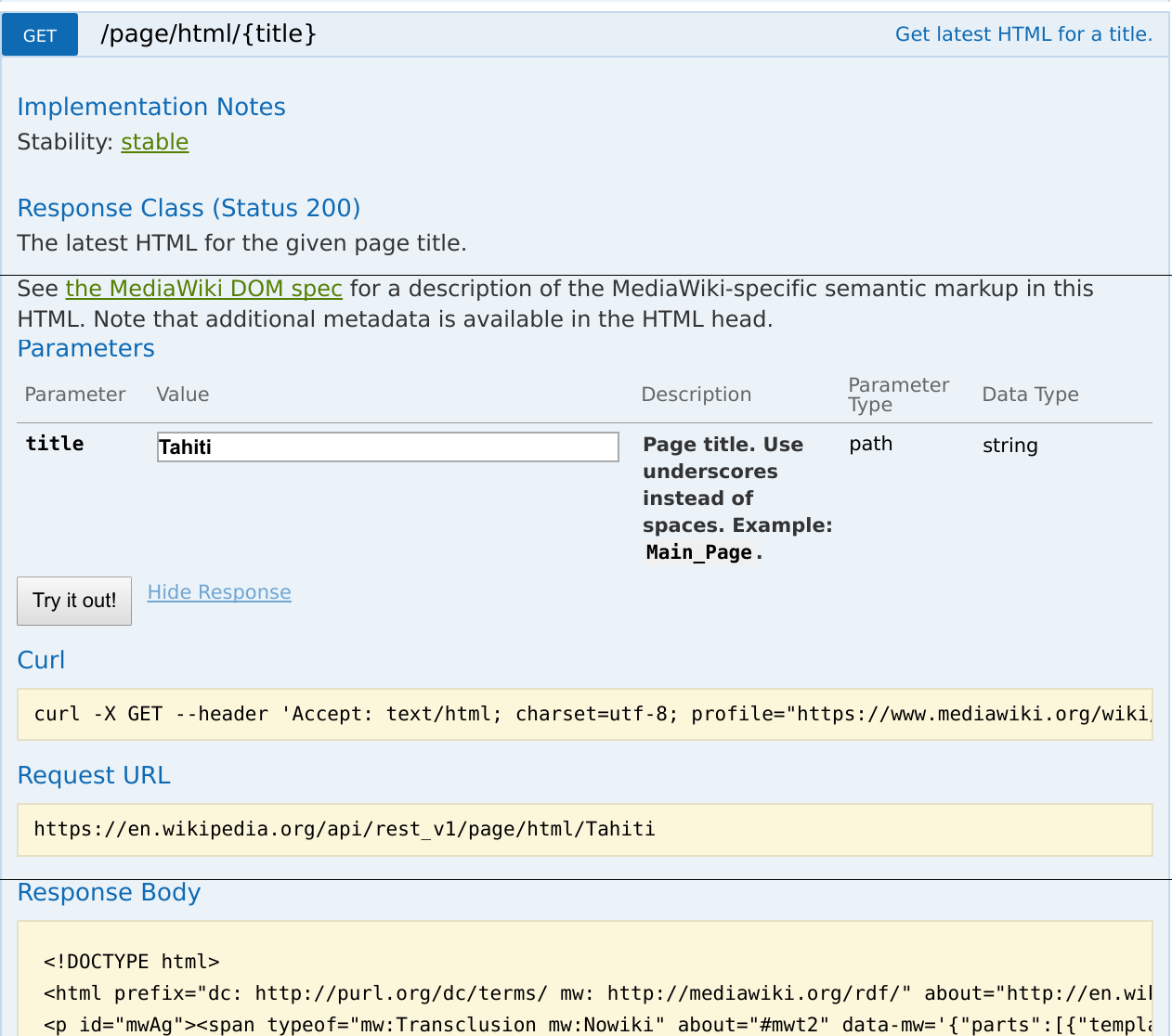
Case study: Structured article HTML
The REST API simplifies working with content using structured and standardized formats. For article content, the Parsing team developed an HTML and RDFa specification exposing a host of structured information inside a regular HTML page. This information makes it possible to easily and correctly process complex content using regular HTML tools.
The VisualEditor WYSIWYG editor (see below) takes advantage of this information to power editing of complex content like template transclusions, media, and extension tags such as citations. The edited HTML is then saved via Parsoid, using its unique ability to cleanly convert edited HTML back to Wikitext syntax. Easy access to the full content information combined with the ability to edit is a huge simplification for anyone interested in working with Wikipedia and other Wikimedia projects’ article contents.
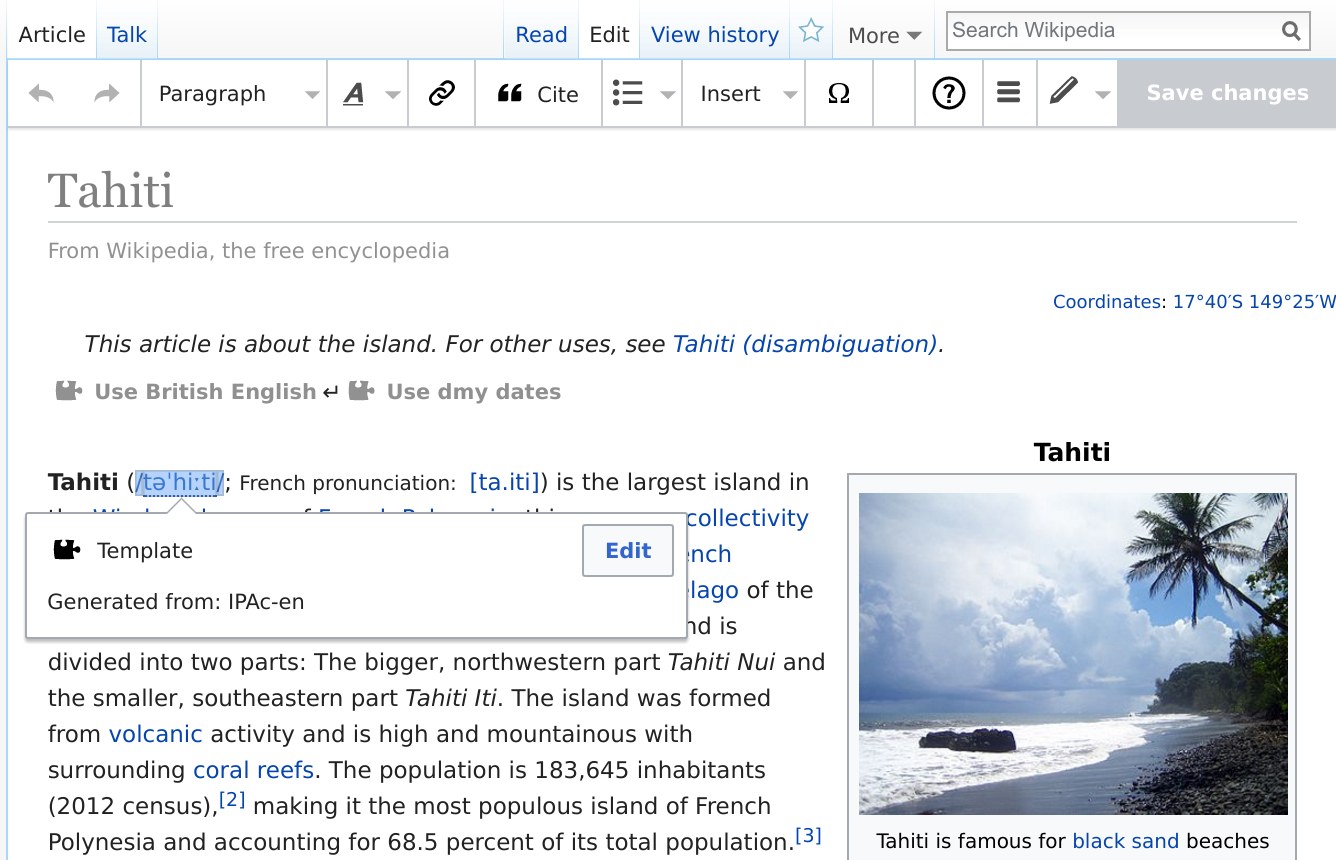
The REST API endpoints used for this are:
- GET /page/html/{title}: Get the latest HTML for a title. Example: https://en.wikipedia.org/api/rest_v1/page/html/Tahiti
- GET /page/html/{title}/{revision}: Get the HTML for a specific revision of a title. Example: https://en.wikipedia.org/api/rest_v1/page/html/Tahiti/771800853
- POST /page/html/{title}: Save the modified HTML for a title. If you only want to convert HTML to wiki markup, you can use the lower level HTML to Wikitext transform end point.
Case study: Page summaries
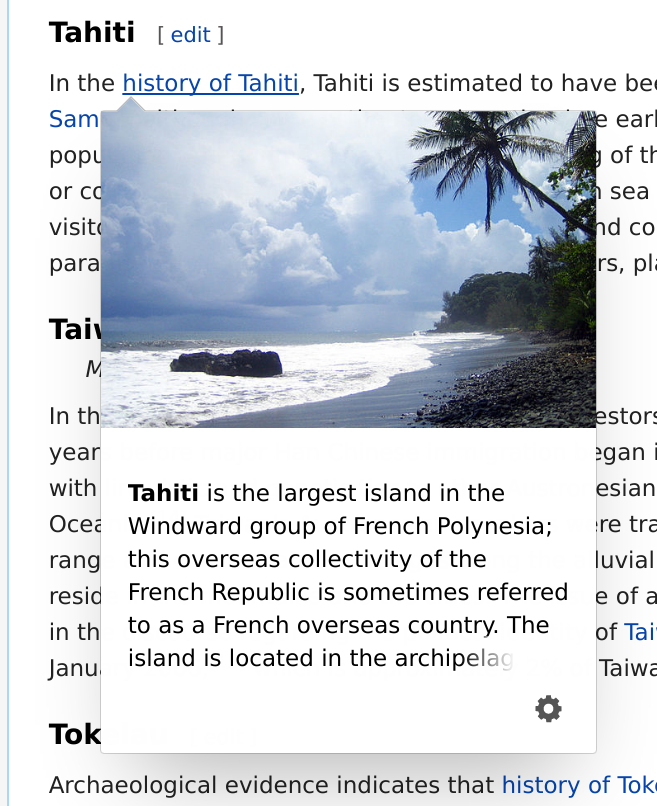
One frequent need is compact summary information about an article in a structured format. To this end, the REST API offers a page summary end point. This endpoint is used to show quick previews for related articles in the Wikipedia Android App. Using the same API, the Reading web team is currently rolling out a similar page preview feature to the desktop web experience.
Other functionality
The Wikipedia Android app has more than eight million users across the globe, and is almost entirely powered by the REST API. The main screen shows a feed of the most interesting and noteworthy articles powered by a set of feed endpoints. Mobile-optimized content is loaded through the mobile-sections endpoints. In an article, the user can get definitions for for words using the definition endpoint offering structured Wiktionary data.
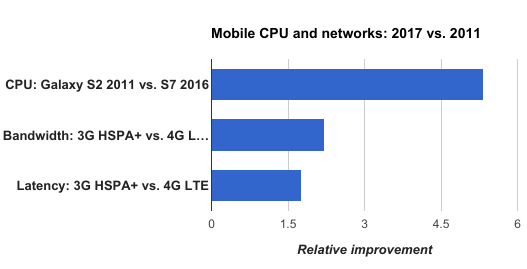 Since 2011, mobile hardware has improved faster than networks.
Since 2011, mobile hardware has improved faster than networks.
Some cross-project information is available at the special wikimedia.org domain. This includes mathematical formulae rendered by Mathoid to SVG, MathML or PNG (also available in each project’s API), as well as historical page view statistics for all projects in the metrics hierarchy.
Technical background
Over the last years, mobile client hardware and platform capabilities have improved at a faster pace than network bandwidth and latency. To better serve our users, we have reduced network use and improved the user experience by gradually shifting more frontend logic to clients. Starting with our Android and iOS apps, content and data is retrieved directly from APIs, and formatted on the client. As we gradually apply the same approach to the web by taking advantage of new web platform features like ServiceWorkers, our APIs are set to serve most of our overall traffic.
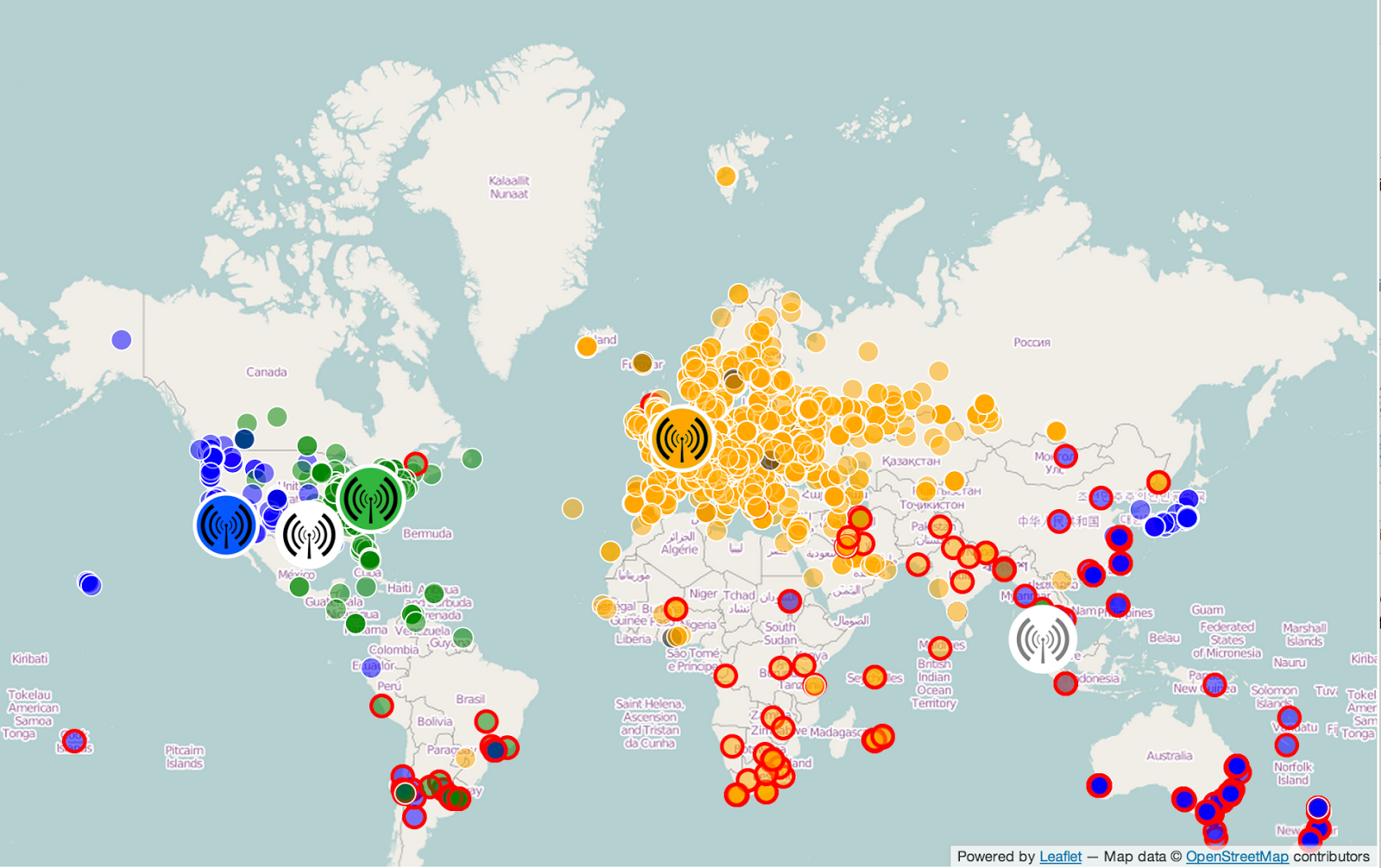
Large volume at low latency is the speciality of our globally distributed caching network. Over 96% of 120k-200k requests per second are served straight from caches, typically from a caching data center geographically close to the client. However, achieving such hit rates requires a clean and predictable URL structure. Our classic action API uses query strings and offers a lot of flexibility to users, but this flexibility also limits the effectiveness of caching. In contrast, the REST API was designed to integrate with the caching layers from the start. Today, over 95.5% of REST API requests are served directly from cache. This directly improves the user experience, shaving dozens to hundreds of milliseconds off of the response time by fully processing most requests in the geographically closest caching data center.
Caching works extremely well to speed up the delivery of popular resources, but does not help with less popular ones. Expensive resources can take dozens of seconds to re-generate from scratch, which ties up server-side resources, and is very noticeable to users. Furthermore, some use cases like visual editing also need guaranteed storage of matching metadata to complete an edit. After using only caching for a while, we soon realized that we needed more than caching; we actually needed storage with explicit control over resource lifetimes. This storage would ideally be available in both primary data centers at the same time (active-active), scale well to accommodate relatively large content types like HTML, and have low operational overheads. After some research and discussion we chose Cassandra as the storage backend, and implemented a fairly flexible REST table storage abstraction with an alternate backend using SQLite.
HyperSwitch: OpenAPI (Swagger) spec driven implementation
The OpenAPI specification (formerly Swagger) is widely used to clearly document APIs in a machine-readable manner. It is consumed by many tools, including the REST API documentation sandbox, our own API monitoring tool, and many of our API unit tests. Typically, such specs are maintained in parallel with the actual implementation, which risks inconsistencies and creates some duplicated effort. We wanted to avoid those issues, so we decided to drive the API implementation entirely with OpenAPI specs using the hyperswitch framework. This move has worked very well for us, and has allowed us to easily customize APIs for 743 projects driven by a single configuration file. A variety of modules and filters implement distributed rate limiting, systematic metric collection and logging, storage backends, content-type versioning, and access restrictions.
Next steps
The v1 release is just the beginning for the REST API. Over the next year, we expect traffic to grow significantly as high-volume features are rolled out, and public adoption grows. Functionality will expand to support high-volume use cases, and experimental endpoints will graduate towards first unstable and then eventually stable status as we gain confidence in each endpoint’s usability.
One focus area over the next year will be preparing a more scalable storage backend for efficient archiving of HTML, metadata and wiki markup. Eventually, we would like to reliably offer the full edit history of Wikimedia projects as structured data via stable URIs, ensuring that our history will remain available for all to use, enabling use cases such as article citations.
We look forward to learning about the many expected and unexpected uses of this API, and invite you to provide input into the next API iteration on this wiki talk page.
Gabriel Wicke, Principal Software Engineer, Wikimedia Services
Marko Obrovac, Senior Software Engineer (Contractor), Wikimedia Services
Eric Evans, Senior Software Engineer, Wikimedia Services
Petr Pchelko, Software Engineer, Wikimedia Services
Wikimedia Foundation
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation