A short while after Wikipedia was created in 2001, contributors started to upload pictures to the site to illustrate articles. Over the years, Wikimedians have accumulated over 22 million files on Wikimedia Commons, the central media repository that all Wikimedia sites can pull from. In addition, nearly 2.5 million other files are spread out across hundreds of individual wikis.
MediaWiki, the software platform used for Wikimedia sites, wasn’t originally designed for multimedia content. We’ve made good progress with better upload tools, for example, but the underlying system still very much focuses on text.
On MediaWiki, each file has a file description page that contains all the information (“metadata”) related to the picture: what it depicts, who the author is, what rights and limitations are associated with it, etc. Many wikis have developed templates (reusable bits of wikicode) to organize such file metadata, but a lot of information is still unstructured in plain wikitext.
The Wikimedia Foundation recently launched an initiative to develop a new underlying system for file metadata using the same technology powering Wikidata. This project is still in the early stages, and even when it becomes available, it will take a long time to migrate the existing metadata to structured data.
The goal of the File metadata cleanup drive is to make the migration process for those 24+ million files less tedious, by making sure that robots can process most of the files automatically.
Machine-readable data also makes it easier to reuse Wikimedia content consistently with best practices for attribution. Examples of tools that use existing machine-readable data include the stockphoto gadget on Commons, WikiWand and Media Viewer. The PDF generator and offline readers like Kiwix are other tools that will benefit from this effort.
Evolution of the file description page
The upcoming Structured data project aims to build a system where you edit the metadata using a form, you view it in a nice format, and robots can understand the content and links between items.

Many files on Wikimedia Commons aren’t actually very far from that model. Many files have an “Information template”, a way to organize the different parts of the metadata on the page. Information templates were originally created to display metadata in a consistent manner across files, but they also make it possible to make the information easier to read for robots.
This is achieved by adding machine-readable markers to the HTML code of the templates. Those markers say things like “this bit of text is the description”, and “this bit of text is the author”, etc. and robots can pick these up to understand what humans have written.
This situation is ideal for the migration, because it tells robots exactly how to handle the bits of metadata and which field they belong to.

If the machine-readable markers aren’t present, the robots need to guess which field corresponds to which type of content. This makes it more difficult to read the metadata, and their parsing of the text is less accurate. The good news is that by just adding a few markers to the templates, all the files that use the template will automatically become readable for robots.

Things become fuzzier for robots when the information isn’t organized with templates. In this case, robots just see a blob of text and have no idea what the metadata is saying. This means that the migration has to be made entirely by human hands.

Fixing files and templates
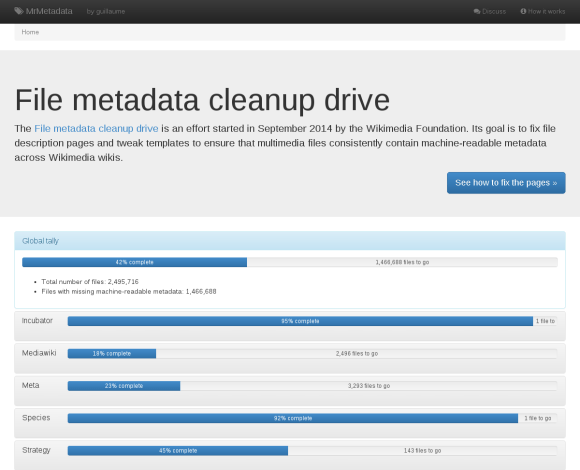
Many files across wikis are in one of the latter states that aren’t readable by robots, and about 700,000 files on Commons are missing an information template as well. In order to fix them so they can be easily migrated in the future requires, we need an inventory of files missing machine-readable metadata.
That’s where MrMetadata comes into play. MrMetadata (a wordplay on Machine-Readable Metadata) is a dashboard tracking, for each wiki, the proportion of files that are readable by robots. It also provides an exhaustive list of the “bad” files, so we know which ones to fix.
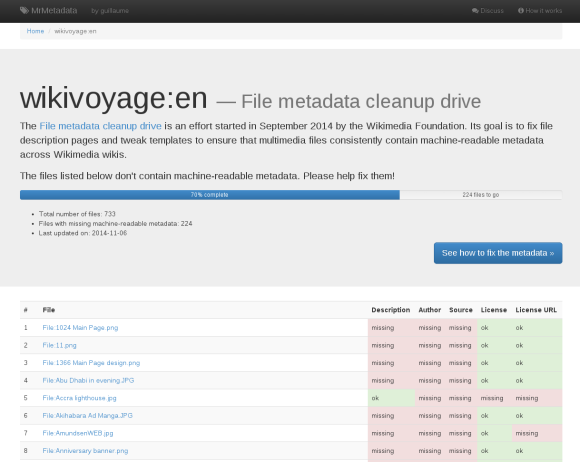
Once the files have been identified, a multilingual how-to explains how to fix the files and the templates. Fixing template is easy: you just add a few machine-readable markers, and you’re done. For example, the English Wikivoyage went from 9% to 70% in just a few weeks. Fixing individual files requires more manual work, but there are tools that make this less tedious.
{kind=link}
Get involved
If you’d like to help with this effort, you can look for your wiki on MrMetadata, bookmark the link, and start going through the list. By looking at the files, you’ll be able to determine if if has a template (where you can add markers) or if you need to add the template as well.
If you add markers to the templates, wait a couple of days for MrMetadata to update, so you can see the remaining files missing machine-readable information. The multilingual how-to provides a step-by-step guide to fixing files and templates.
The Wikimedia Foundation is starting this cleanup effort, and you’re encouraged to help on Commons and on your wiki. Ultimately, the decisions in the transition to machine-readable templates will be up to you.
I’m going to be available as a resource for volunteers who need support. If you have questions or encounter odd edge cases, you can contact me on IRC (I’m guillom in the #wikimedia channel on freenode), on the cleanup drive’s talk page, on the tech ambassadors mailing list, or via EmailUser.
Starting next week, I’ll also be holding “Cleanup Wednesdays”, with several IRC support sessions during the day to rotate across time zones. The first sessions (listed at IRC office hours) will be happening on Wednesday, November 12 at 18:00 (UTC), and a few hours later on Thursday, November 13 at 04:00 (UTC).
I’m hoping that you’ll join this effort to organize file metadata and make it more readable for robots, in order to make the future transition to structured data as painless as possible for humans.
Guillaume Paumier, Wikimedia Foundation
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation